DataX Writer插件实现了写入数据到StarRocks目的表的功能。在底层实现上,DataX Writer通过Stream Load以CSV或JSON格式导入数据至StarRocks。内部将Reader读取的数据进行缓存后批量导入至StarRocks,以提高写入性能。阿里云DataWorks已经集成了DataX导入的能力,可以同步MaxCompute数据到EMR StarRocks。本文为您介绍DataX Writer原理,以及如何使用DataWorks进行离线同步任务。
背景信息
DataX Writer总体的数据流为Source -> Reader -> DataX channel -> Writer -> StarRocks。
功能说明
环境准备
测试时可以使用命令python datax.py --jvm="-Xms6G -Xmx6G" --loglevel=debug job.json。
配置样例
从MySQL读取数据后导入至StarRocks。
{
"job": {
"setting": {
"speed": {
"channel": 1
},
"errorLimit": {
"record": 0,
"percentage": 0
}
},
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "xxxx",
"password": "xxxx",
"column": [ "k1", "k2", "v1", "v2" ],
"connection": [
{
"table": [ "table1", "table2" ],
"jdbcUrl": [
"jdbc:mysql://127.0.0.1:3306/datax_test1"
]
},
{
"table": [ "table3", "table4" ],
"jdbcUrl": [
"jdbc:mysql://127.0.0.1:3306/datax_test2"
]
}
]
}
},
"writer": {
"name": "starrockswriter",
"parameter": {
"username": "xxxx",
"password": "xxxx",
"database": "xxxx",
"table": "xxxx",
"column": ["k1", "k2", "v1", "v2"],
"preSql": [],
"postSql": [],
"jdbcUrl": "jdbc:mysql://172.28.**.**:9030/",
"loadUrl": ["172.28.**.**:8030", "172.28.**.**:8030"],
"loadProps": {}
}
}
}
]
}
}相关参数描述如下表所示。
参数 | 描述 | 是否必选 | 默认值 |
username | StarRocks数据库的用户名。 | 是 | 无 |
password | StarRocks数据库的密码。 | 是 | 无 |
database | StarRocks数据库的名称。 | 是 | 无 |
table | StarRocks表的名称。 | 是 | 无 |
loadUrl | StarRocks FE的地址,用于Stream Load,可以为多个FE地址,格式为 | 是 | 无 |
column | 目的表需要写入数据的字段,字段之间用英文逗号(,)分隔。例如, 重要 该参数必须指定。如果希望导入所有字段,可以使用 | 是 | 无 |
preSql | 写入数据到目的表前,会先执行设置的标准语句。 | 否 | 无 |
postSql | 写入数据到目的表后,会先执行设置的标准语句。 | 否 | 无 |
jdbcUrl | 目的数据库的JDBC连接信息,用于执行preSql和postSql。 | 否 | 无 |
maxBatchRows | 单次Stream Load导入的最大行数。 | 否 | 500000(50W) |
maxBatchSize | 单次Stream Load导入的最大字节数。 | 否 | 104857600 (100M) |
flushInterval | 上一次Stream Load结束至下一次开始的时间间隔。单位为ms。 | 否 | 300000(ms) |
loadProps | Stream Load的请求参数,详情请参见Stream Load。 | 否 | 无 |
类型转换
默认传入的数据均会被转为字符串,并以\t作为列分隔符,\n作为行分隔符,组成CSV文件进行Stream Load导入操作。类型转换示例如下:
更改列分隔符,则loadProps配置如下。
"loadProps": { "column_separator": "\\x01", "row_delimiter": "\\x02" }更改导入格式为JSON,则loadProps配置如下。
"loadProps": { "format": "json", "strip_outer_array": true }
DataWorks离线同步使用方式
在DataWorks上创建工作空间,详情请参见创建工作空间。
在DataWorks上创建测试表并上传数据到MaxCompute数据源,详情请参见建表并上传数据。
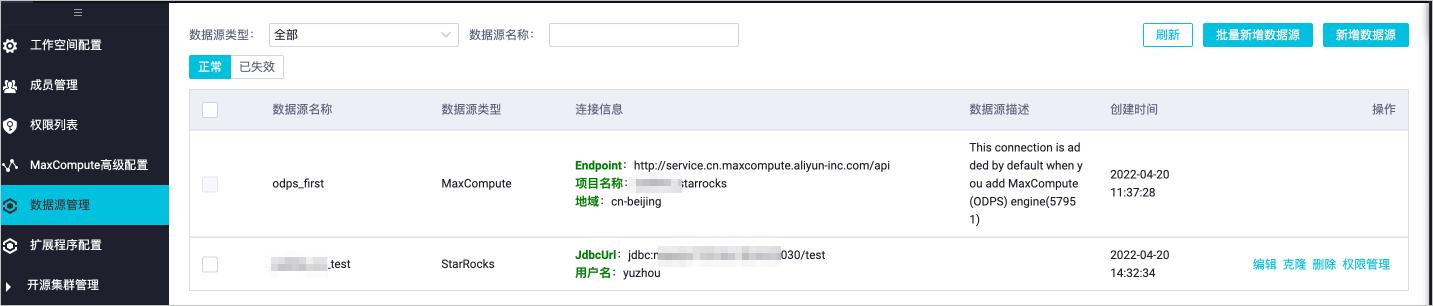
创建StarRocks数据源。
在DataWorks的工作空间列表页面,单击目标工作空间操作列的数据集成。
在左侧导航栏,单击数据源。
单击右上角的新增数据源。
在新增数据源对话框中,新增StarRocks类型的数据源。
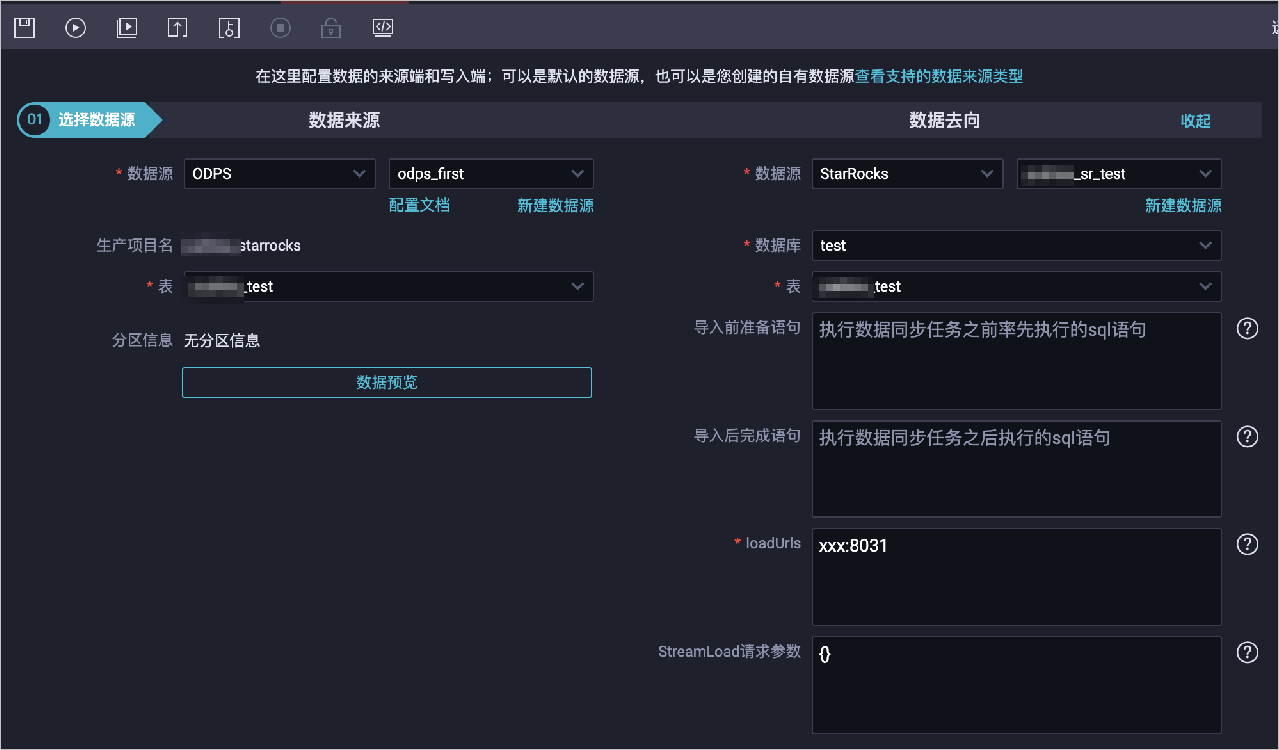
创建离线同步任务流程。
新建业务流程,详情请参见创建业务流程。
在目录业务流程,新建离线同步任务,详情请参见通过向导模式配置离线同步任务。
在StarRocks集群中查看数据,详情请参见快速入门。
- 本页导读 (1)